After being side-tracked for the past 6 months or so, and after the successful release of v13 of Bookends, I thought I would revisit this topic.
I am attempting to use Ulysses and Bookends together. But not just for exporting to MS Word to submit to publishers, but also to post directly online via Wordpress, Medium and other online services. Ideally, I'd like to be able to scan HTML with temporary citations as initially discussed in this topic. But I understand this is not an trivial undertaking.
So I've been experimenting for most of the day attempting to find a workflow that can achieve this with current features, but I am stymied at every turn.
Past experiments with scanning HTML were problematic due to the abundance of curly braces. So I have attempted to do the scanning against the markdown source in Ulysses. Here is what I have tried.
Scanning Markdown as a text document - using defaults
Using the default citation options from Bookends and adding temporary citations to my Ulysses document, I can then copy my Ulysses sheet to an external folder (because Ulysses uses iCloud storage API which does not expose a Filesystem interface outside of Ulysses). This causes some of the advanced Ulysses markdown to disappear, but that's a separate issue. From there, I can then use the Biblio -> Scan Document option from Bookends to scan the markdown text file.
As already known, the problem is it attempts to parse any instance of curly braces { } as bookends temporary citations, such as those related to code blocks. This would be okay except where bookends attempt to reconcile code blocks containing curly braces as temporary citations, it changes the curly braces to brackets ( ).
As a further test, I added some JSON containing curly braces to a MS Word (version 16.23) document and then also added citations using the Bookends toolbar option 'insert citation'. Again within the Bookends toolbar, I then selected 'scan document' and it still attempted to scan my JSON as citations and changed the curly braces to brackets in MS Word. This I image would be an issue for anyone writing a paper that includes curly braces for purposes other than citations.
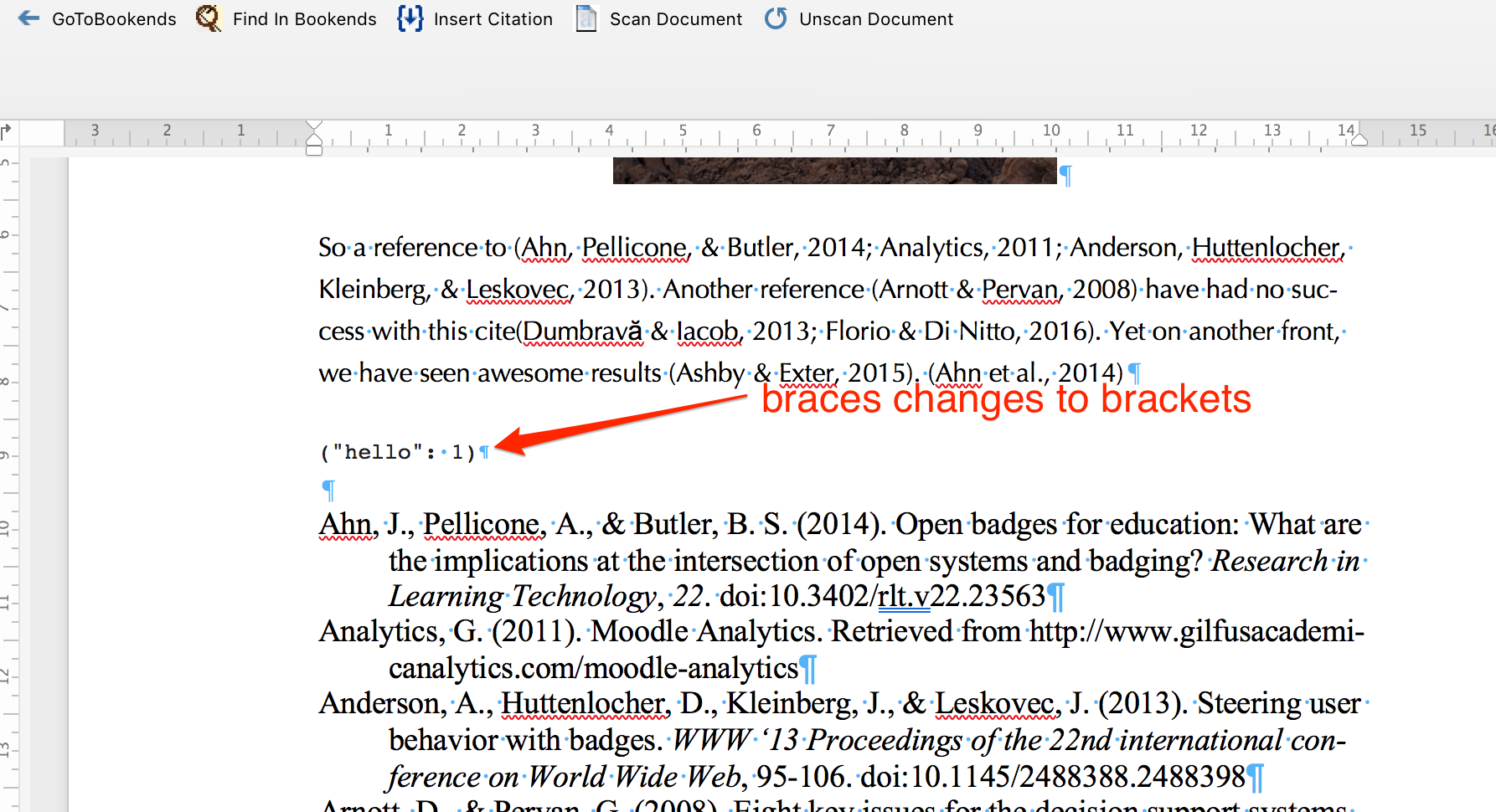
Question: I am wondering whether there could be an option in the scan document feature that you can be selected that will leave any 'unmatched' temporary citations (i.e. those that aren't actually temporary citations) unchanged. The upshot would be that while I would receive a list of warnings about unmatched cases, the curly braces would remain unchanged and the document would remain correct.
Scanning Markdown as a text document - testing different citation delimiters
So I tried using some of the other delimiters that are on offer [] [[]] <<>> || etc. Sadly they all interfere with Markdown syntax, other programming language syntax or otherwise run into the limitations of Ulysses external folder markdown formatting. So I next tried the 'bibtex' delimiter option in the same menu.
The hope was that it would insert the temporary citation as something like this (using APA6th):
\cite{Rutherford et al., 2015, #15612}
Having \cite{ as an opening delimiter is much less likely to cause parsing issues by the document scanner, but I can't get it to work.
It didn't add the \cite in front - it looks the same as the {} delimiter option.
If I turn on Bibtex in that part of the settings, it works, but then it uses the bibtex key field. I don't want to use bibtex keys.
Question: Is it possible to have more options for temporary citation delimiters? Can custom delimiters be selected for instance? For my usage case, double curly braces would work well {{}} and are actually the standard option in Ulysses Markdown. In code, they can be separated by white space in most instances and still be valid code.
If anyone has any suggestions for workflows that they use to achieve this multi-publishing goal, I'd be most appreciative.
Cheers,
Damo.